
Running a private benchmark for a DDD implementation skill
How to measure whether an agent skill actually helps - and how to tell a real difference in scores from statistical noise.

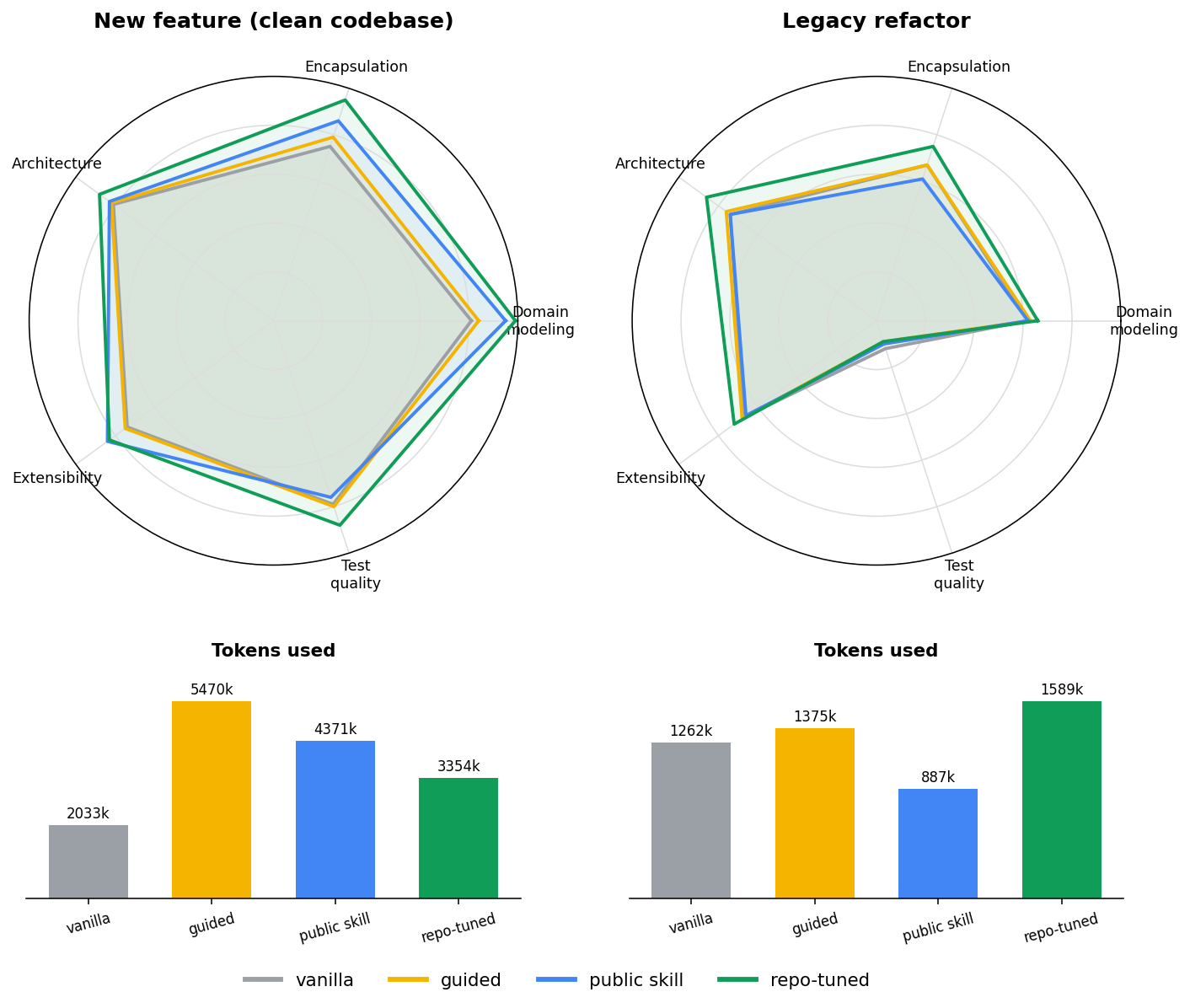
Our previous post argued that every AI tooling decision needs measurement on your own codebase. Here is what that looks like in practice: we measured a public DDD skill on two real C# tasks. On a clean new feature it lifted quality sharply. On a legacy refactor the headline score barely moved - and yet, under that flat number, the same skill was quietly rebuilding four quality dimensions out of five. None of that is visible from a single score, or from a README. You only see it by measuring, dimension by dimension - and this is how we measured.
How we benchmark a public skill
We took a public DDD skill from GitHub, Nick Tune’s tactical-ddd skill, and checked whether it actually improves the code a coding agent writes on real domain-driven work. Then we used NASDE, our open-source benchmarking toolkit, to answer it with numbers instead of opinions.
We ran this across a batch of DDD tasks. We chose two of them for a deeper analysis here, because they show the same point from two sides: different codebases and tasks respond differently to the same skill, and automated measurement lets you see that almost immediately.
The setup, in brief:
Two illustrative tasks. A new feature on a clean DDD/hexagonal codebase (add a weather-based discount that calls an external API), and a legacy refactor from an anemic codebase with fat services to a clean domain model. We picked work that differs on purpose, so we’d see whether the skill’s value holds across situations.
Four configurations of the same agent, model held constant:
the bare vanilla model with no skill (our baseline)
the model guided with hand-written, super-short DDD hints in its instructions
the public skill used as-is
the public skill tuned to each repository’s conventions.
Five quality dimensions, scored by an LLM-as-a-judge: domain modeling, encapsulation, architecture compliance, extensibility, and test quality. Scores normalized to 0-1.
If you want to run something like this yourself, that’s exactly what NASDE is for: you define the configurations, point them at tasks built from your own repositories, and it runs each one in isolation and scores the output against the dimensions you care about. The full task definitions and agent configs for this experiment are public in the repository.
One discipline runs underneath everything below: we never trust one measurement. Every configuration was run several times, and every run was scored several times. We explain why, and what it buys you, in the measurement section near the end.
When the skill pays off
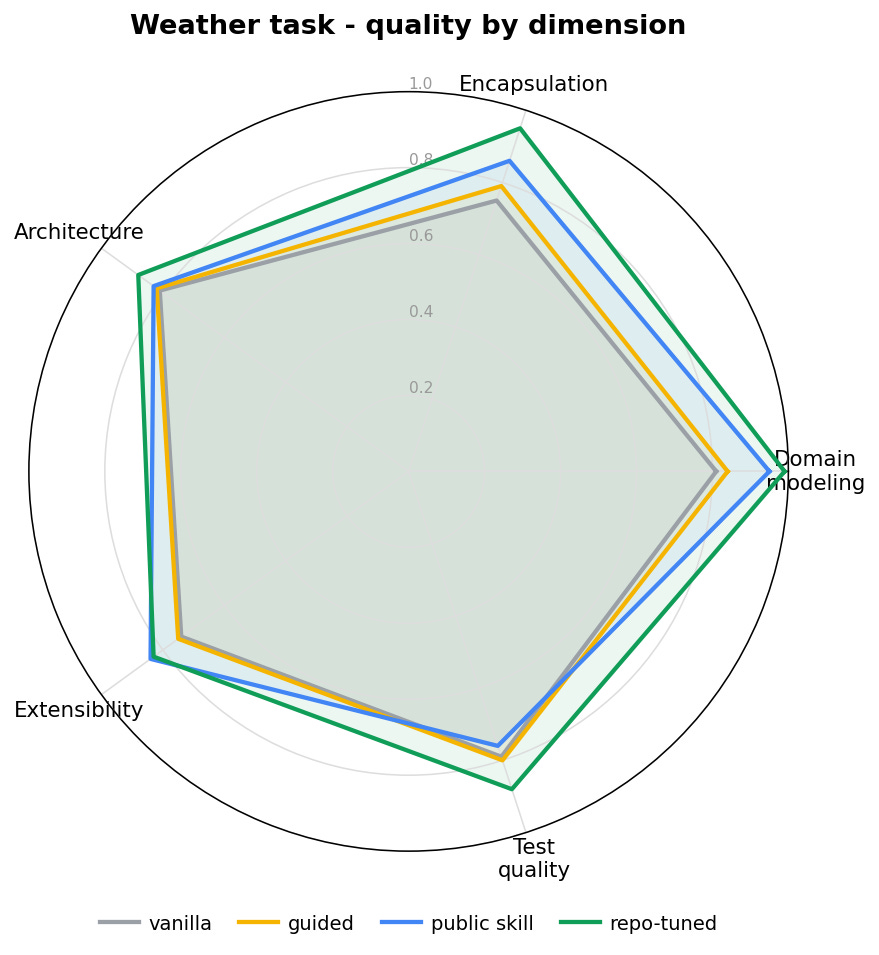
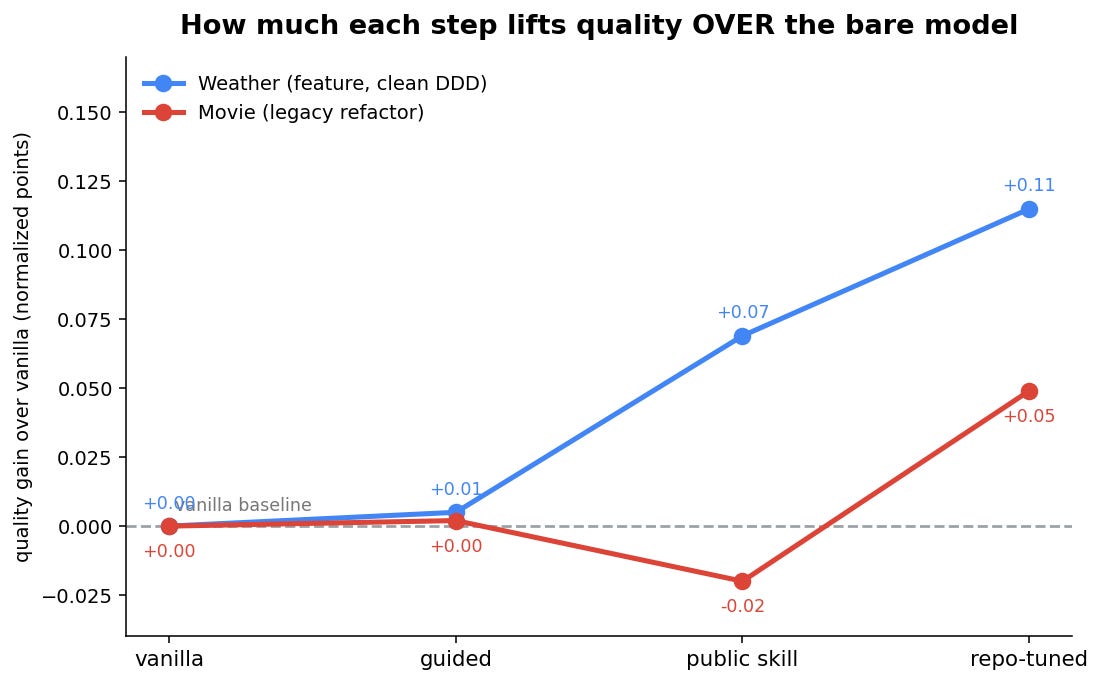
On the new-feature task, on a clean codebase, the skill did what you’d hope, and tuning it to the repo did more.
The bare model already writes decent DDD, adapting reasonably to the surrounding patterns - its overall score was 0.79. Hand-written guidelines changed nothing measurable (0.80, statistically indistinguishable from the bare model - hold that thought, it matters later). The public skill was the first thing to genuinely move the score: 0.86, a real step above the bare model. Tuning that skill to the repository’s own conventions pushed it further still, to 0.91.
The interesting part is where the gains land. Per dimension, they concentrate exactly where the skill teaches: domain modeling and encapsulation fill out almost the entire quality space. On this task the tuned skill extracted fifteen value objects from the domain - the bare model wrote a handful. That is the skill reshaping the design, not just decorating it.
And it does that without costing more. Here’s the operational side of the same task - tokens and wall-clock time per configuration:
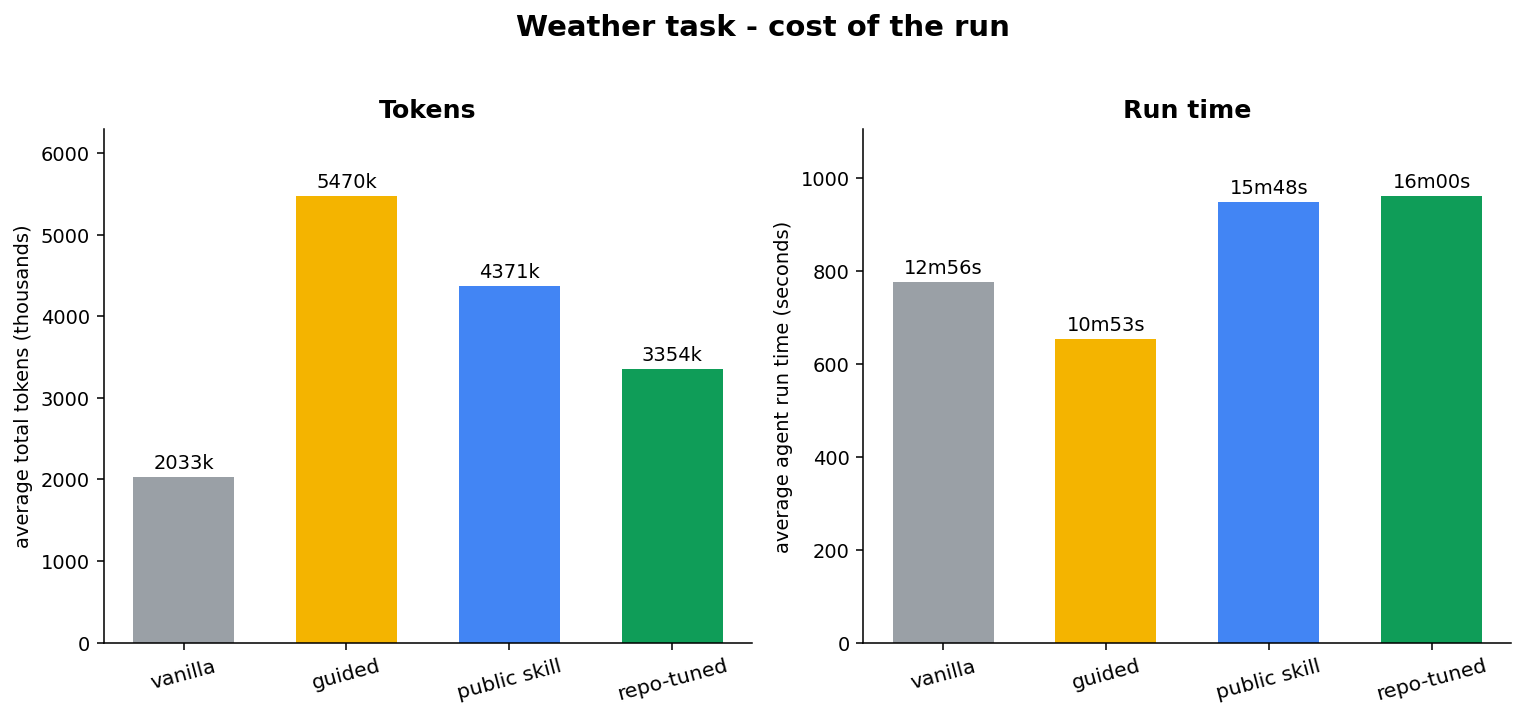
Look at the token panel. The best-scoring configuration, the repo-tuned skill, spends fewer tokens than either the guided model or the off-the-shelf skill. A structured skill is more focused, not more wasteful: it knows what to build, so it explores fewer dead ends. Run time barely separates from the baseline. On clean work, the quality the skill buys is close to free.
This is the marketing-friendly result. A skill helps, tuning it to your repo helps more, and it doesn’t even cost extra. If every task looked like this, the advice would be easy.
The legacy refactor: where the headline lies
The second task looks, at first, like the skill gave up.
On the legacy refactor the four configurations barely separate on the headline number: bare model 0.56, guidelines 0.57, public skill 0.54, repo-tuned 0.61. The off-the-shelf public skill even scored below the bare model - installing it as-is bought nothing. Only the repo-tuned skill rose clearly above the baseline, and only by a fraction of what it managed on the feature task. Read that single number and the verdict writes itself: don’t bother tuning a skill for legacy work.
That verdict is wrong, and seeing why is the most useful thing in this post. Break the one score into the five dimensions it averages over, and the repo-tuned skill turns out to significantly improve four of them over the bare model: architecture compliance (the biggest move), encapsulation, domain modeling, and extensibility. The fifth, test quality, sits on the floor - for every configuration, the bare model included - because nobody wrote real tests on this repo. The skill teaches domain design, not testing; testing is simply outside what it reaches. And because that one floor-level dimension is averaged in with the rest, it pulls the headline down and hides the four real gains underneath.
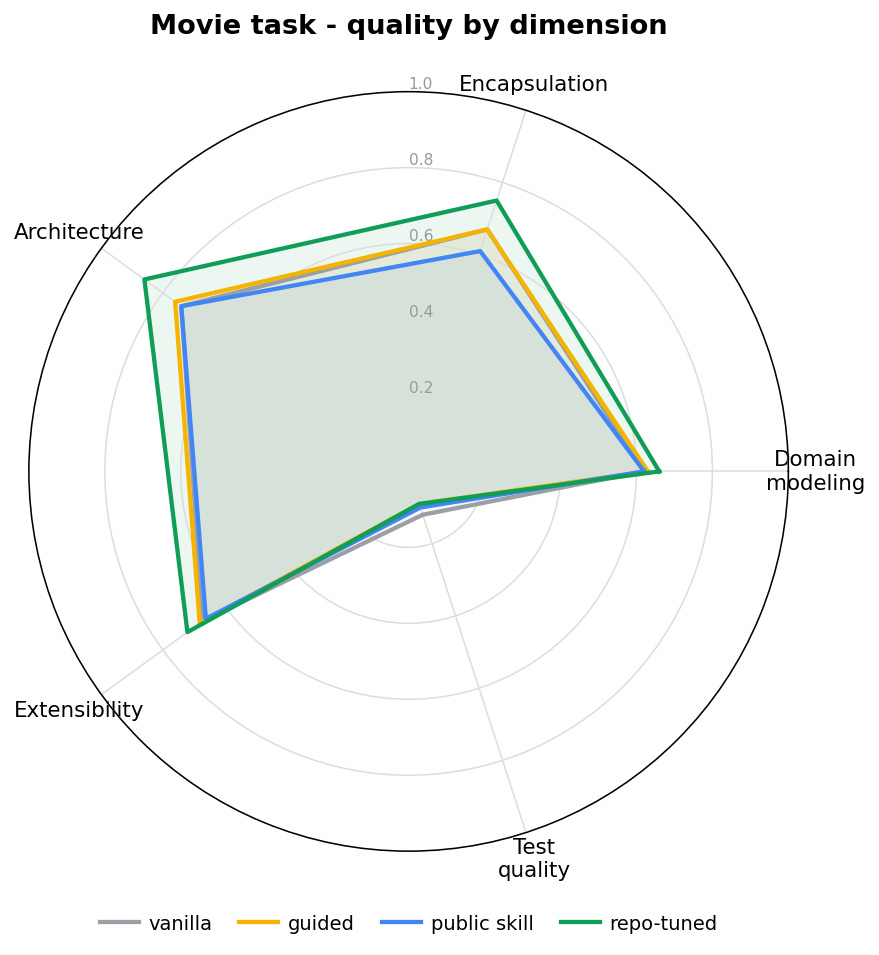
So the honest summary of the legacy task is not “the skill barely helped.” It is: the skill measurably rebuilt the design - architecture, encapsulation, modeling, extensibility - and the one axis it was never meant to touch dragged the average back down to look like nothing happened. The aggregate is a headline. The decision lives in the breakdown.
Notice this is a different set of dimensions than the feature task leaned on. On the clean feature the gains piled into domain modeling and encapsulation; here the strongest move is architecture compliance. Same skill, different tasks, different dimensions lit up - which is the real shape of the thing:
How much a skill helps, and on which dimensions, is set by the task and the codebase - not by how hard you tune it. A clean greenfield feature gives the skill room to reshape the design, and the gain is large and shows up even in the aggregate. A constrained legacy refactor fixes much of the shape in advance, so the same skill, tuned the same way, moves fewer dimensions and a bruised dimension can mask the rest. You don’t get to assume which case you’re in. You measure it - per dimension.
The cost picture is worth a look too:
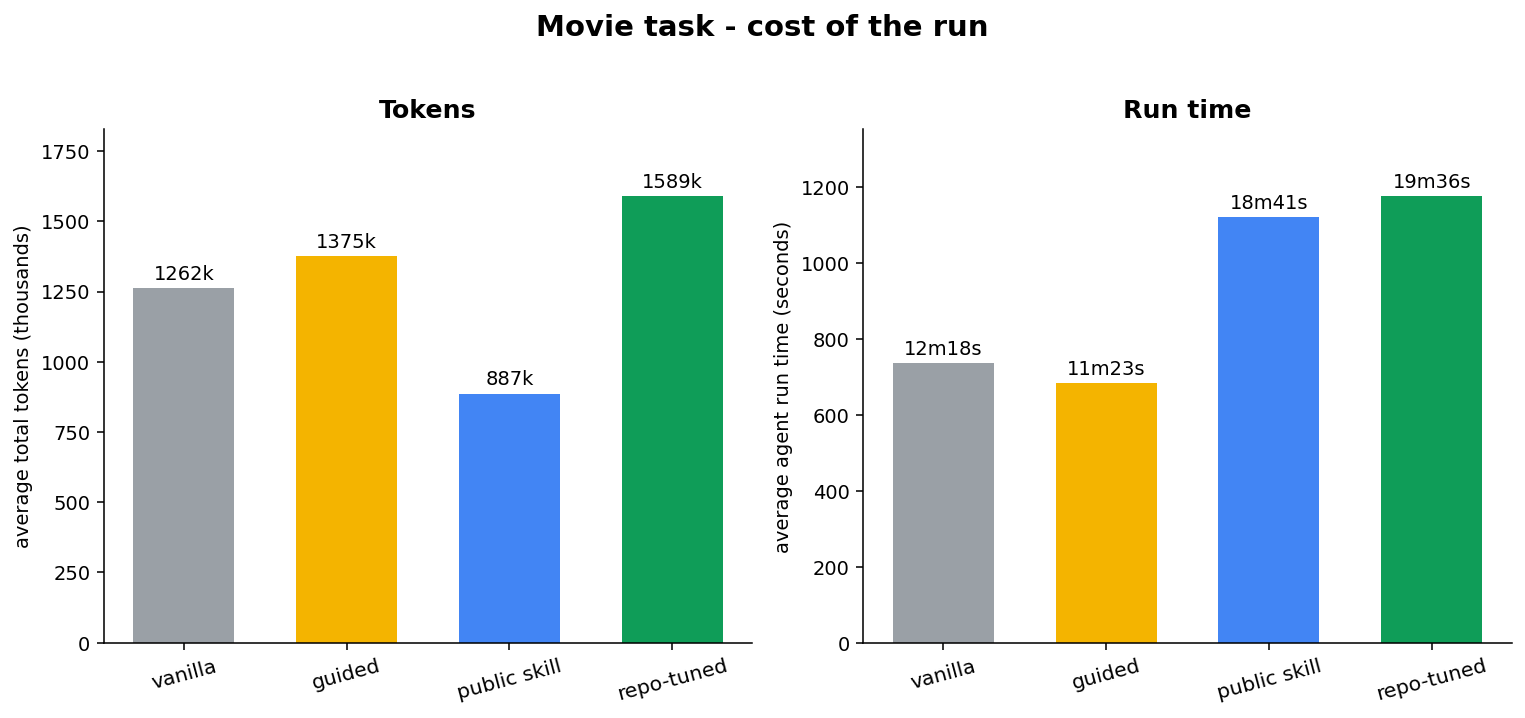
On the hard task the public skill is the cheapest of all four in tokens and still doesn’t beat the baseline - so “better must mean more tokens” is plainly false. The real cost shows up as time: the skill configurations run about 1.5x longer than the bare model (roughly 18-19 minutes against 12). The skill buys a better first draft by spending thinking time, and it spends the most of it where the problem is tangled. The gain isn’t free, but the price is time on hard tasks - not tokens, and not in proportion to the quality you get.
Why we measure everything more than once
Every number above is an average over repeated runs, each scored several times. That isn’t caution for its own sake - a single measurement genuinely would have misled us.
Early in the refactor runs, one reading looked alarming: the public skill scored well on one run and noticeably worse on the next, almost down to baseline. Was the skill unreliable on messy code? On one measurement each, that’s exactly what the data said. It wasn’t true - it was noise, and there are two distinct kinds of it hiding in any single score:
Evaluator noise: the judge scoring the same code differently between readings.
Agent noise: the agent writing different code between runs of the same configuration.
The fix for both is the same: repeat. We score each piece of code several times to settle the judge down, and we run each configuration several times and average, so a single odd run can’t speak for the whole. (Exactly how those two repetitions divide the work is a detail we come back to at the end.) Every number in this post is one of those averages, not a single reading.
With the averages in hand, we can compare them: public skill 0.86, repo-tuned 0.91. Is that a win?
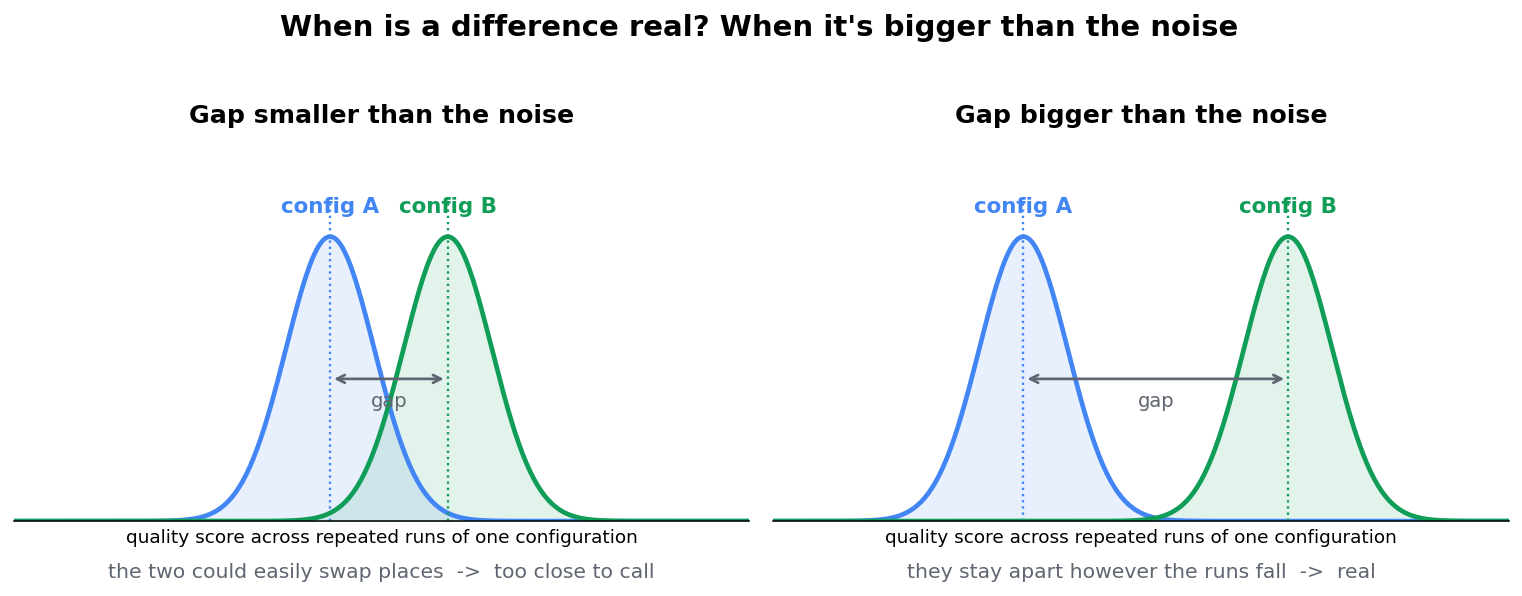
Not so fast. Each average still came from only a few runs, and a few runs can come out high by chance. The honest question is the one any engineer asks of a flaky test: is this gap bigger than the random variation we’d see just from running the same configuration again? Answer that and “looks better” becomes “is better.” Get it wrong and you ship a skill change that was really just a lucky run.
Picture each configuration’s runs as a little cloud of scores. If the two clouds barely touch, the gap between their averages is real; if they sit largely on top of each other, the gap is just noise and the two could swap places on a rerun.
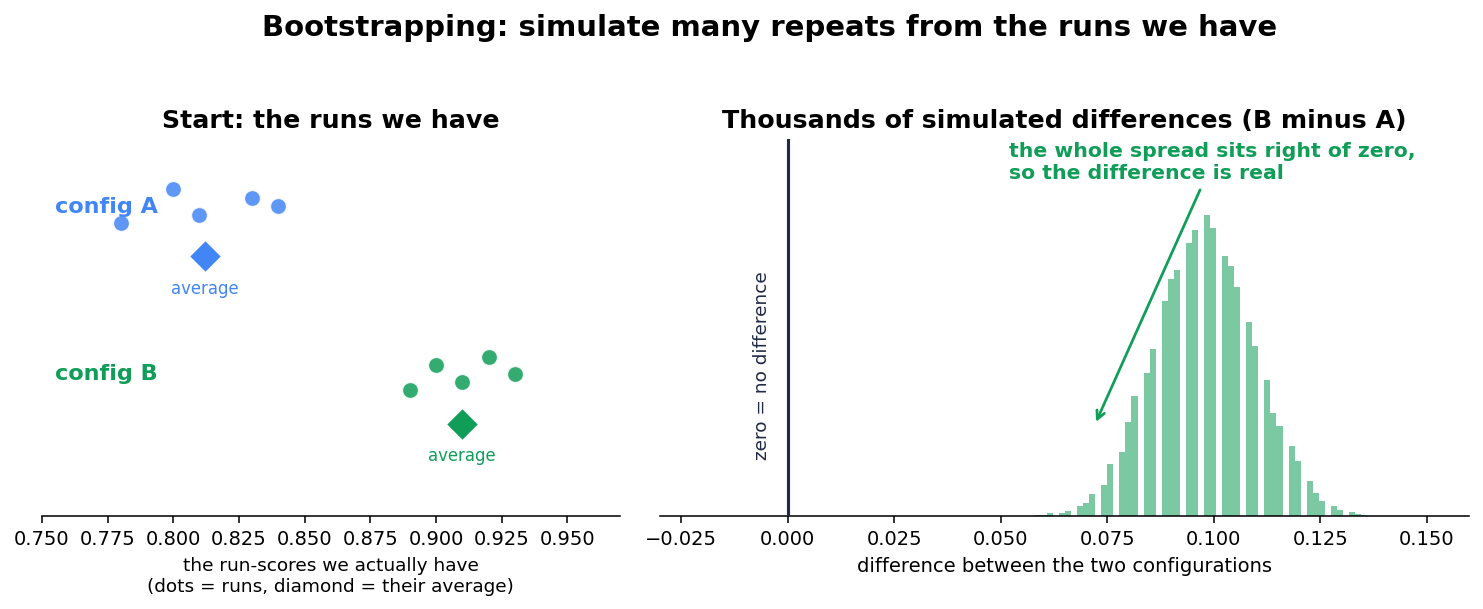
So how do we tell? Rather than actually repeat the whole experiment many times, we simulate those repeats, using only the runs we already have. The technique is called bootstrapping:
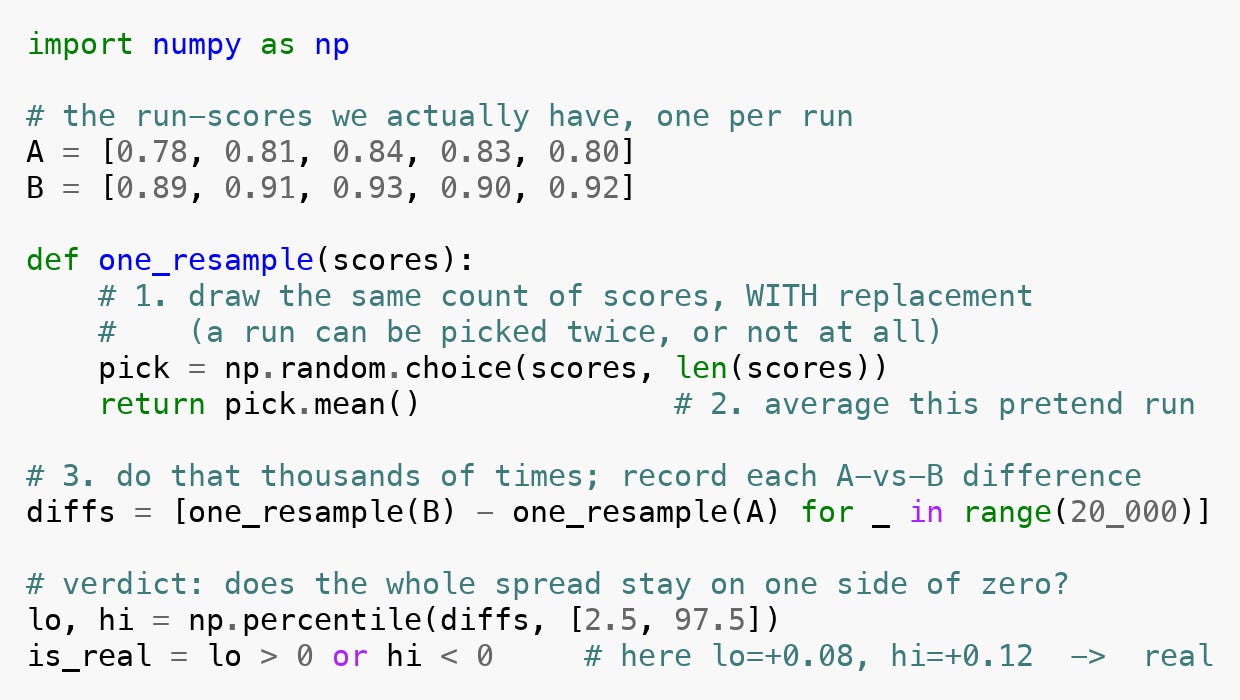
Build a pretend repeat of the experiment. Take the scores we actually got for a configuration and pick the same number of them back out at random, allowing repeats - so one run can be counted twice and another not at all. That gives a slightly different set than we started with: a believable version of how another run of the experiment might have turned out. Average it.
Do this thousands of times, for both configurations. Each time we get a fresh pretend-average for each one, and we record the difference between them. We never launch a single extra agent run; we only keep re-drawing from the scores we already have.
Look at the spread of those differences. Thousands of pretend repeats give thousands of possible gaps between the two configurations - the full range of how the comparison could have come out on a luckier or unluckier day.
The verdict is then just a question of where that spread sits. If all of it stays on one side of zero, the difference holds no matter how the runs are resampled - it is real. If the spread sits across zero, then many of those pretend repeats show no difference at all, or even a reversed one, and we call it too close to call.
This is the actual code behind the picture above - the three steps, then the zero test.
We don’t run that test on the aggregate, though - the aggregate is exactly the number that misled us on the legacy task. We run it per dimension. Here is one dimension, encapsulation, across both tasks - eight comparisons, each with its plausible range and the zero line:
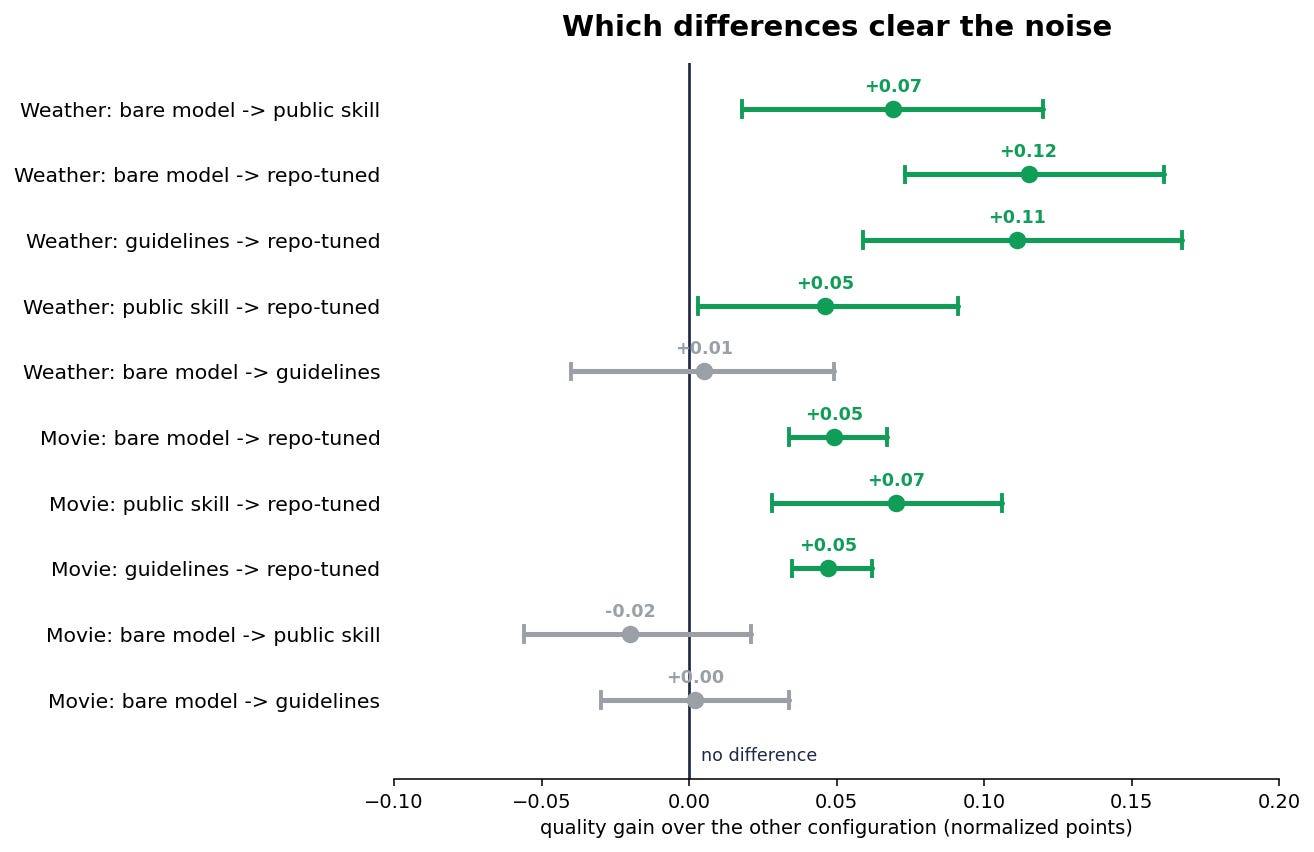
One dimension replays the whole post. Green bars are real, grey bars are noise, and the pattern lines up on both tasks:
The repo-tuned skill beats the bare model on encapsulation on both tasks (+0.18 on Weather, +0.08 on Movie). Both real.
Guidelines do nothing, on either task - the two bars sit dead on zero. A few sentences of DDD advice in the prompt is, as far as we can measure, a placebo. The structured skill is not.
The public skill helps only on greenfield. Real on Weather (+0.10); on the legacy refactor it sits below the bare model and well inside the noise - off-the-shelf, it does nothing there.
On the legacy task, tuning clearly beats the off-the-shelf skill (+0.14, real) - the very gain the aggregate had buried. Read the headline number alone and you’d never see it; read this one dimension and it’s unmistakable.
Full results available here.
A note for the statistically inclined: bootstrapping is not the only tool here. We chose it because it is the easiest to show - the three-line shuffle above, which anyone can reproduce. For small samples like ours, the commonly recommended choice is a more sophisticated, Bayesian approach (it is what Cameron R. Wolfe reaches for in Applying Statistics to LLM Evaluations, a clear, practical guide to doing statistics on LLM evaluations properly - well worth reading in full). We ran a Bayesian method on these same numbers too (results here), and the conclusions do not change - the same differences come out real, the same ones stay lost in the noise. A proper comparison of the two approaches deserves its own piece; here it is enough that the answer does not depend on which one you pick.
What else could be fooling us?
But wait - what about the judge’s noise? We named two kinds of noise at the start, then spent all our effort on the agent’s. Did we forget the evaluator’s?
We didn’t; we dealt with it earlier, by averaging. Scoring the same piece of code several times shows us the judge’s spread on its own - around 0.01 to 0.03 on a single reading. The judge’s noise is small enough that averaging its readings into one score per run is all bootstrapping needs to stay reliable. The bootstrap can’t pull that leftover judge noise back out from the agent’s; it just folds into the overall noise, which at this size is something we accept, not a problem we solve.
There is a related boundary worth making explicit. Averaging judge readings reduces noise, but it does not calibrate the metric itself. A stable judge can still be systematically wrong about a dimension. Calibrating coding-agent metrics against human review, execution results, and repository-specific expectations is a separate layer of evaluation, and one we’ll cover in a follow-up post.
A different source of uncertainty sits upstream of both, and it doesn’t show up as spread at all: whether the skill even fires.. We took this uncertainty out of the test by instructing the agent to invoke the skill explicitly, and NASDE records the invocation count on every run so we could confirm it fired. The general lesson stands regardless: present is not the same as used, and if you don’t track invocation you may be benchmarking a skill that never ran.
One more thing worth clarifying: the number of samples. We lean on bootstrapping and the Bayesian check because running hundreds of the same task is expensive - more so today, with token costs climbing. However, a hundred-plus runs per configuration would unlock a whole set of sharper statistical tools - telling the different sources of noise apart, or confirming a result is real to far higher precision. We read our ranges as “this gap clearly stands apart from the noise,” not as a certificate; for a question this size, five runs and a resampling test are enough. But when the stakes are higher, the right answer is more runs, not more faith in a few. For the curious, Wolfe’s article is again the place where all these trade-offs are laid out cleanly.
So: measure
This experiment doesn’t end in a verdict on one DDD skill. It ends somewhere more useful.
A public skill is worth trying, and tuning it to your repository is usually worth more. But how much it helps, and on which dimensions, depends on the task and the codebase - and a single headline score will sometimes tell you the opposite of the truth, the way it nearly told us a tuned skill was pointless on legacy code. You cannot read any of this off a README, a star count, or someone else’s results.
The only way to get your answer is to measure on your own code, with repetition, and per dimension - because the dimension is where the decision actually lives. That is what NASDE does, and it’s open-source: github.com/NoesisVision/nasde-toolkit. The skill we tested is public, the repositories are public, and the methodology is the point. Point it at a skill your team is weighing, and the question stops being a debate.
Coming next in this series: the same measurement approach applied one level up, to the harness itself. When a new agent lands, or you’re weighing a move between Claude Code and Codex in either direction, the honest answer is rarely “X is better” in the abstract; it’s “better on the work your team actually does.” We’ll show how to put two harnesses on the same tasks and let the per-dimension scores, rather than the launch-day hype, settle which one fits your codebase.
NASDE (Noesis Agentic Software Development Evaluation) is an open-source toolkit for evaluating AI coding agents on tasks drawn from real codebases. It is part of the Noesis Vision portfolio of tools for AI-native software development.