
Why every AI tooling decision needs a measurement
Which agent? Which skill? Which model? In 2026 these are weekly calls with budget and codebase consequences — and almost no one is making them with data from their own codebase


The decisions are expensive. The methods are not serious.
In 2026, an engineering team makes a stream of decisions that did not exist three years ago:
Which coding agent does the team standardize on?
Is this new skill from Twitter(X) worth adopting team-wide, or is it a toy?
Did Monday’s model upgrade make the PRs better, or just more expensive?
That MCP server we wired up last sprint — is it earning its place, or is it noise?
Each one carries budget and codebase consequences. Each one is, today, almost universally made on feel. The team likes it. It seems faster. Twitter is excited about it. The new model scored higher on a public leaderboard.
At the same time, engineering teams do not deploy refactors without running tests. They do not merge changes that fail the quality gate. They have decades of practice catching regressions before they reach production.
Then the same teams adopt a new agent, a new skill, a new MCP server — changes that affect the daily output of every developer — with no equivalent check. Not because they would not run one, but because that check has not yet entered the workflow. The discipline exists; the practice does not.
This is the gap. Not a shortage of agents. Not a shortage of intelligence. A shortage of measurement that lives inside your own codebase.
Public benchmarks will not save you
The reflex answer is: “But we have benchmarks. SWE-bench. HumanEval. The leaderboards.”
Two problems.
Your codebase is not in those benchmarks. SWE-bench tests agents against issues from Django, scikit-learn, sympy. Real repositories — public ones. Your internal monorepo, with its conventions, its domain abstractions, its weird-but-load-bearing patterns, exists in no benchmark suite anywhere.
Every frontier model has read those public repositories thousands of times. Django and Flask are deep in every training corpus. A 70% score on SWE-bench partially reflects how well the model remembers those repos. Your private codebase exists in no training set. An agent at 70% on SWE-bench might land at 30% on the equivalent problem from your git history. Or higher. You cannot know without running it.
The benchmarks tell you can this model write code at all. That question stopped being interesting a year ago. The question now is can this agent contribute to my codebase, judged by my team’s standards. No public leaderboard answers it. You have to measure it yourself.
What we built so we could stop guessing
We built NASDE — the Noesis Agentic Software Development Evaluation toolkit. Open-source, lives at github.com/NoesisVision/nasde-toolkit, and built on two existing pieces: Harbor for isolated agent execution, Opik (optional) for trace and score storage. NASDE itself contributes the evaluation project structure, the from-git-history task pipeline, and the multi-dimensional reviewer-agent scoring on top.
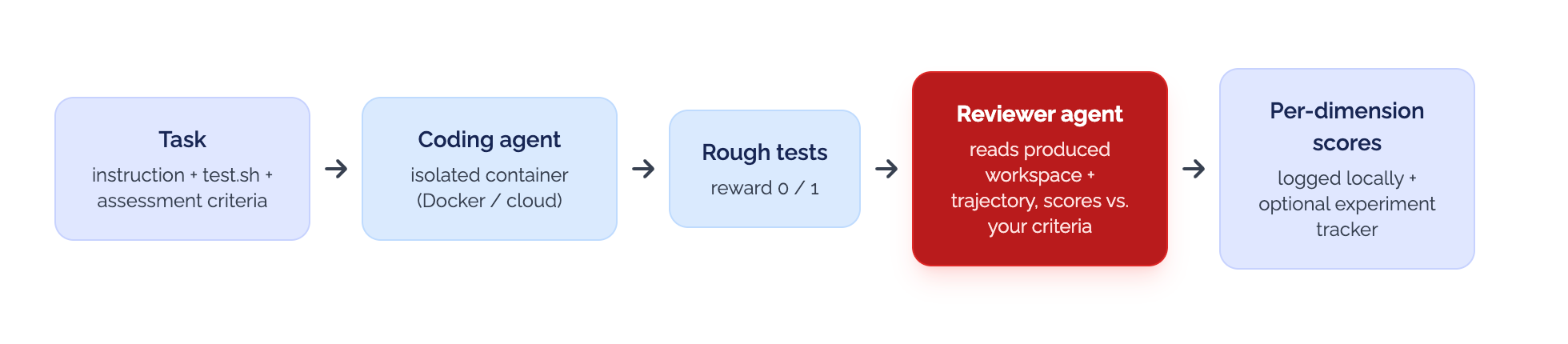
The shape of it is simple:
A benchmark is a set of tasks built from your own git history. Closed PRs, fixed bugs, completed refactors. Real problems your team actually solved. The toolkit includes a pipeline that turns those into runnable tasks with starting state, instructions, and a reference solution.
The unit you score is the full agent configuration, not the model alone. Model + skills + MCP servers + harness. This is what actually lands on a developer’s machine, so this is what gets evaluated.
Scoring is multi-dimensional, weighted by what your team values. You define the dimensions that matter for your work — correctness, architectural alignment, code quality, completeness, whatever fits. As many as you need, weighted however you want. An LLM-as-a-Judge model evaluates each output against the criteria you defined; how strict or how generous it is, is also up to you.
It runs across vendors and runs in CI. Same benchmark, Claude Code, Codex, Gemini, or whatever comes next month, same scoring. Re-run on every model release. Watch the scores move, or not.
Two solutions to the same task can both pass every test. One respects your architecture, one is a brittle workaround that happens to compile. Pass/fail rates them identical. Multi-dimensional scoring does not. That is the whole point.
Proof over promise — run it yourself
NASDE keeps the evaluation loop local and agent-native. Benchmarks live on your disk as plain files. Scoring runs through coding agents that already know how to traverse a codebase (like Claude Code or Codex). No proprietary scoring service in the middle, no data round-trip to a vendor’s cluster, no lock-in to anyone’s evaluation stack.
The whole pipeline is built to be tried on a developer’s laptop in one sitting — no UI to log into, no platform to stand up, no hosted service to subscribe to. Just a CLI, the agent you already use, and the project on disk. Once it works locally, the same configuration drops into CI without changes.
How to start? Open the repo, follow the install instructions, and you have a CLI on your machine — nasde init, nasde run, nasde eval. The same setup ships with a set of NASDE-aware skills you can install into your own coding agent, so designing benchmarks, generating tasks from git history, and inspecting runs becomes a conversation in the agent rather than a CLI lookup.
Once installed, the workflow is the one already familiar from the agent: ask for a new benchmark task, ask for a run, ask for a comparison of two variants. Recent agent benchmarks suggest CLIs are often a sharper fit than MCP integrations for this kind of work, which is why NASDE stays CLI-first and surfaces itself through skills rather than through a server in the middle.
The example below is one of our own benchmarks, run against an internal skill variant we wanted to validate. Different teams will define different benchmarks; the mechanics are the same.
A typical run is one command, like:
nasde run --variant claude-guided --attempts 3 --with-opik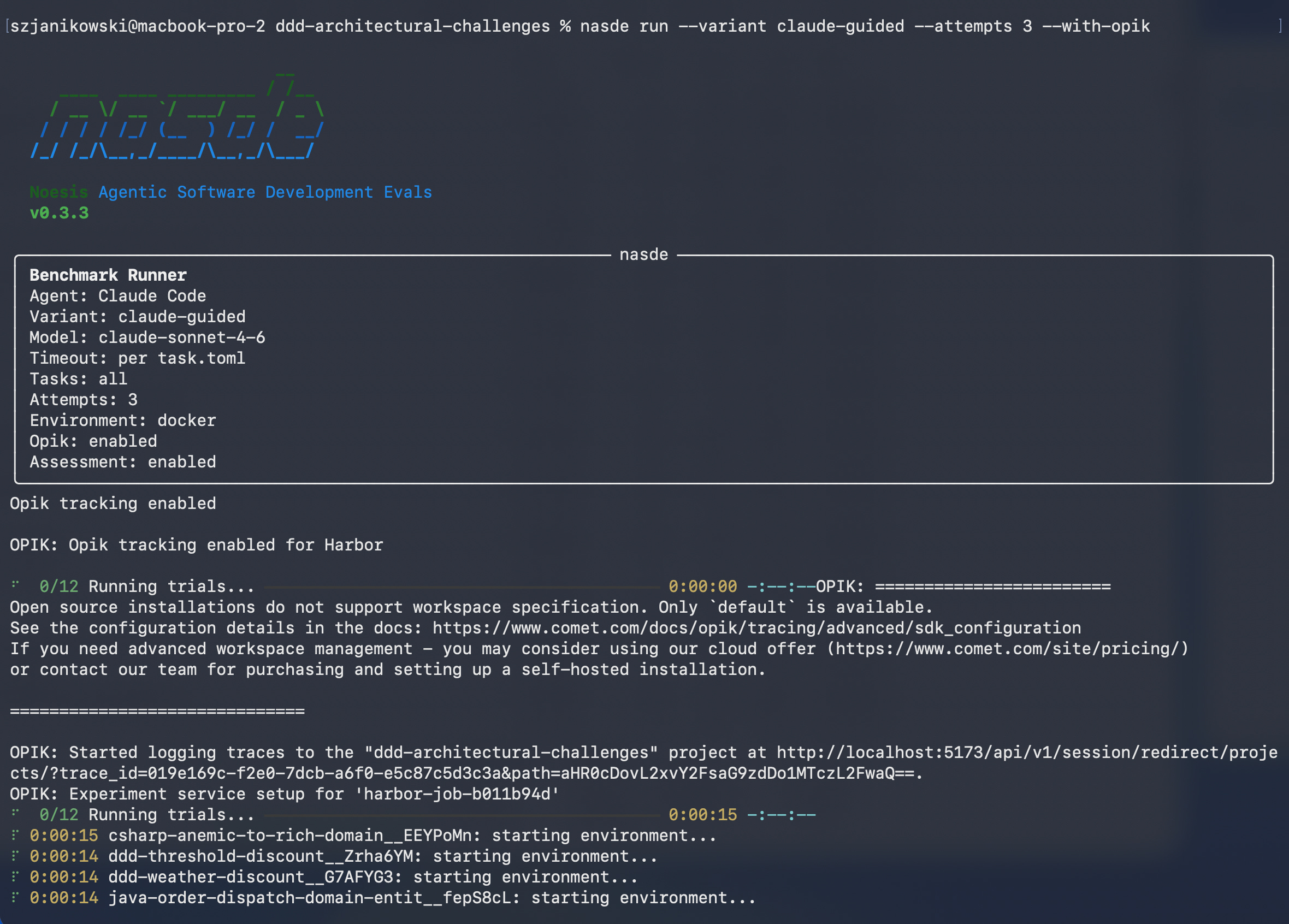
The CLI prints a summary of exactly what is about to be measured, then runs each task in an isolated environment, captures the agent’s full trajectory, and scores the output against the dimensions you defined. Trials run in parallel; tracing into Opik is one flag (--with-opik).
When the run finishes, the results sit in one view, ready to be compared:
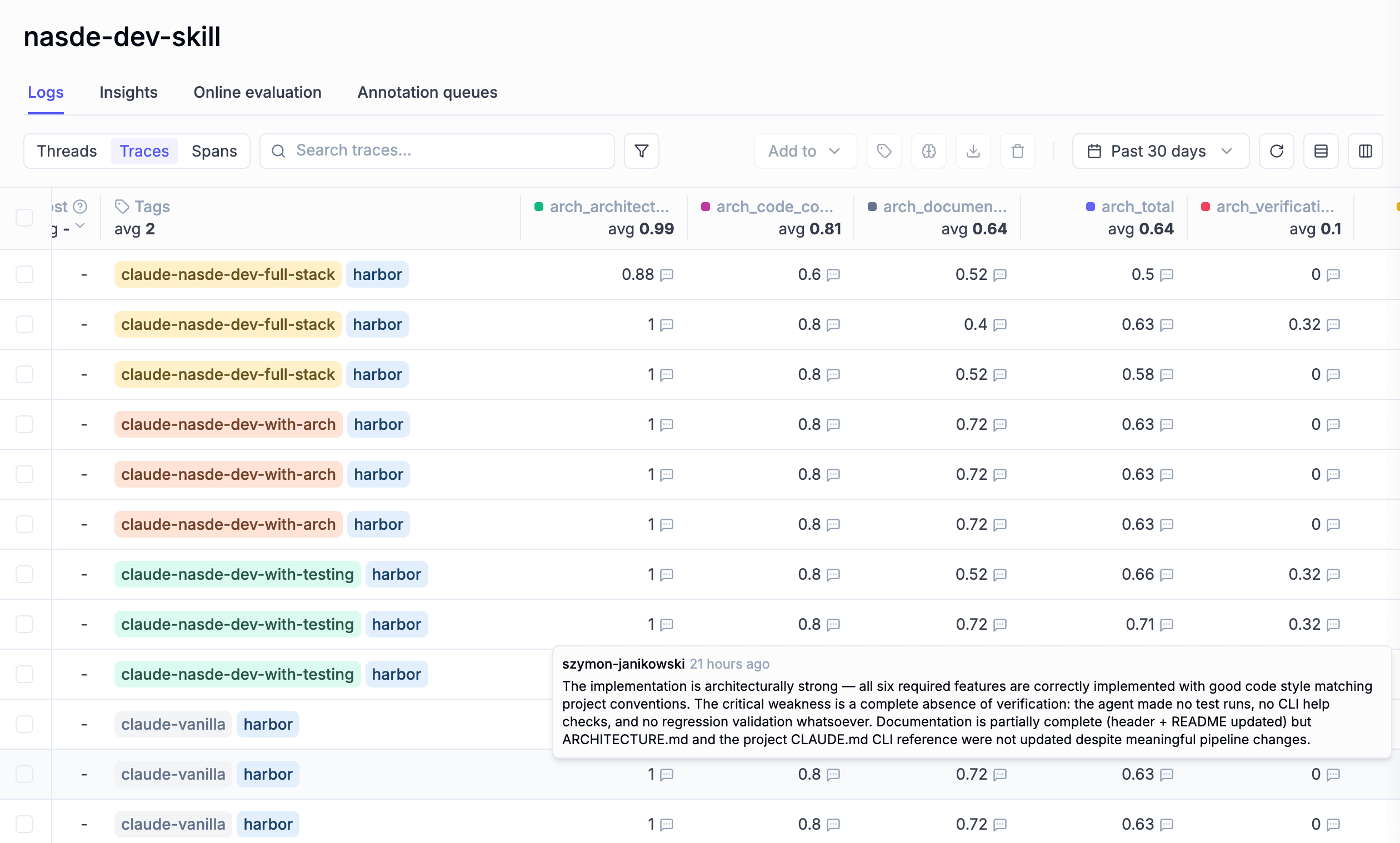
This is exactly the question the post opened with, answered: which agent configuration is actually better for the work this team does — broken down by the dimensions that team chose to score. Different setup against the next. Same tasks. Same scoring scheme. Numbers next to numbers, with the trace of every run available for inspection in Opik — ready for human overview, annotations, and comments.
If you would rather not run Opik, the results land on disk as structured files — point your coding agent at the run directory and ask for a summary; it will read the trial outputs, the per-dimension scores, and the trajectories, and tell you which variant won on what.
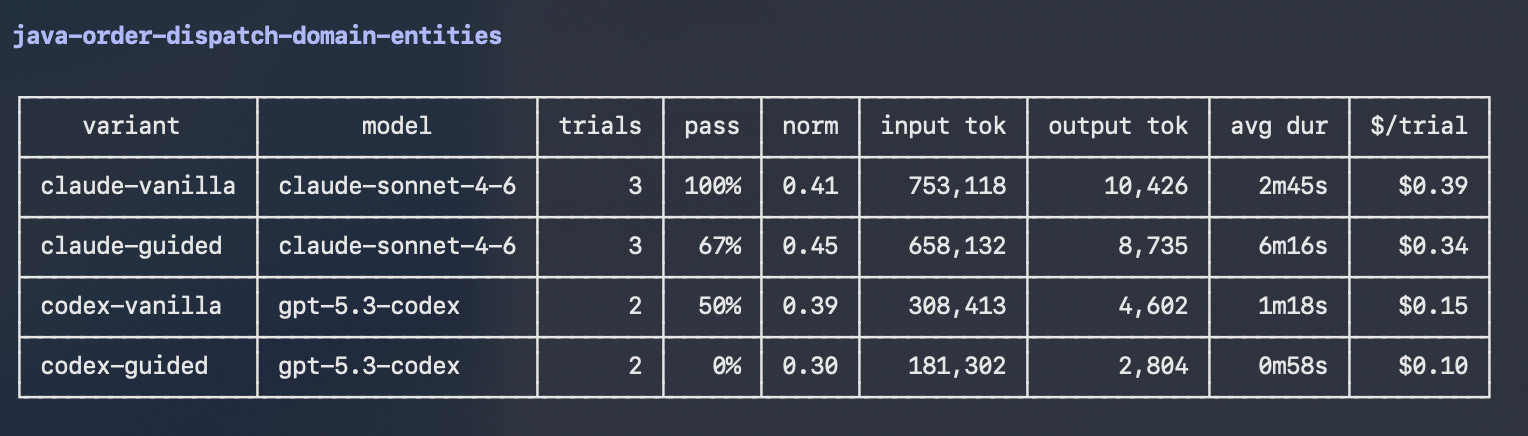
That is what replaces “it feels cleaner.”
What NASDE will not do for you
NASDE will not tell you whether you can trust your agent. It will tell you how its output compares to another configuration on tasks your team actually cares about. That is less than most benchmarks promise. It is also the only thing that actually informs the decisions you are already making this week.
If your team is changing agents, adding skills, swapping models, or wiring up MCP servers, those decisions are being made on something. Across the engineering teams we work with, that something is, today, impression and habit. It does not have to remain so, and you do not need our involvement to change it — the toolkit is open.
Coming next in this series: why the agent itself is usually the least interesting variable in the equation — and what you should actually be tuning instead. Follow us to get updates about the new posts!
NASDE is open-source: github.com/NoesisVision/nasde-toolkit. If you run it on your own repo and the results surprise you, we want to hear about it.